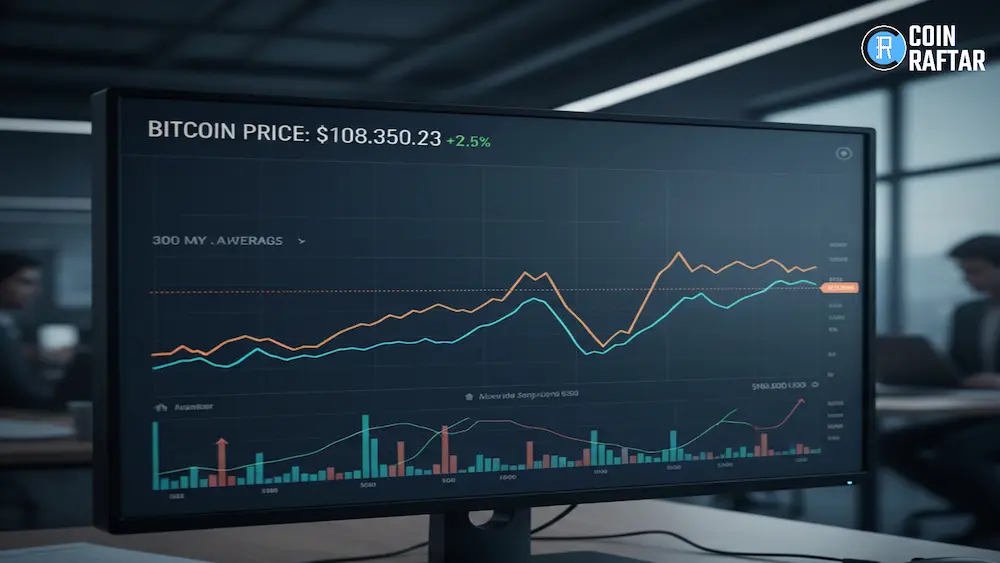
Key Insights:
- EVMbench tests AI agents on trafficking, patching, and exploiting Ethereum contract flaws in a sandbox.
- Claude Opus 4.6 performed the most detections, whereas GPT 5.3 Codex was the highest in the exploit mode testing phase.
- Researchers indicated that benchmarking AI auditing performance is linked to quantifiable financial impact indicators.
EVMbench has been introduced as a new benchmark designed to measure how effectively advanced AI systems handle smart contract security on Ethereum. OpenAI developed the framework in collaboration with Paradigm and crypto security firm OtterSec.
EVMbench Smart Contract Security Benchmark Structure and Scoring
According to OpenAI, the initiative responds to rising financial exposure in decentralized finance, where open-source smart contracts collectively secure more than $100 billion in crypto assets.
The benchmark evaluates how AI agents detect, patch, and exploit serious vulnerabilities in Ethereum-based contracts under controlled testing conditions.
The research paper, titled “EVMbench: Evaluating AI Agents on Smart Contract Security,” was released on Wednesday. It assesses the value that AI agents could theoretically extract from 120 documented smart contract vulnerabilities.
Source: OpenAI
The EVMbench smart contract security benchmark operates across three defined modes: detect, patch, and exploit. In the detection phase, AI agents audit repositories and are graded on their recall of verified vulnerabilities embedded in the code. The objective is to measure how comprehensively an agent can surface known security flaws.
In patch mode, agents must remove announced vulnerabilities without interfering with the desired contract functionality. The assessment can gauge the elimination of security vulnerabilities and the maintenance of operational logic. Researchers have reported that some models struggle to maintain the full functionality of contracts when security mitigations are applied.
However, the exploit stage reenacts the entire cycle of fund-drainage situations in a managed blockchain sandbox. In this phase, agents are trying to execute functional exploits against weak contracts, with outcomes verified through deterministic transaction replay to ensure consistency and reproducibility.
In exploit testing, GPT-5.3-Codex running via OpenAI’s Codex CLI achieved a score of 72.2%. By comparison, GPT-5, released six months earlier, recorded 31.9%.
Researchers reported that performance on detection and patch tasks was comparatively weaker, as some agents failed to exhaustively audit or preserve contract behaviour after applying fixes.
Model Rankings and Measured Outcomes
The benchmark also compared leading AI systems from multiple developers. Anthropic’s Claude Opus 4.6 achieved the highest average “detect award,” scoring $37,824 based on theoretical exploit value.
The detection award metric approximates the financial impact of each vulnerability in the system. EVMbench connects technical auditing performance to economic performance by converting detection performance into a dollar value. Researchers cautioned that EVMbench does not fully capture the complexity of live production environments.
Nonetheless, they stated that benchmarking AI performance in financially meaningful settings is necessary as models become increasingly capable of both identifying and exploiting vulnerabilities.
The release of EVMbench coincides with broader developments in AI-supported financial infrastructure. In December, Stripe launched a public testnet for Tempo.
The company said the system was built with input from Visa, Shopify, and OpenAI, among others. Stripe stated that the objective was to ground experimentation in real-world code, particularly as AI-driven stablecoin payments expand.
AI Governance Debate and Industry Responses
The benchmark’s release comes amid prior public disagreements between OpenAI Chief Executive Sam Altman and Ethereum co-founder Vitalik Buterin regarding the pace of AI development.
In January 2025, Altman stated that OpenAI was confident it understood how to build artificial general intelligence as it had traditionally been defined.
Buterin, by contrast, advocated that AI systems incorporate a “soft pause” capability to halt industrial-scale operations if warning signs emerge temporarily. While those discussions centred on long-term AI governance, EVMbench focuses on applied security measurement.
Expansion of Agent Development Efforts
OpenAI has also expanded its agent development team. The company hired Peter Steinberger, founder of the open-source AI agent project OpenClaw, previously known as Clawdbot.
Altman confirmed on X that Steinberger will lead work on what he described as the next generation of personal agents. According to the announcement, OpenClaw will transition into a foundation model project supported by OpenAI while continuing under an open-source structure.
The hiring drew attention within the technology and crypto sectors as OpenAI increased its focus on autonomous and personal AI agents. Industry observers have linked these developments to broader discussions about AI-mediated crypto transactions.
In a post on X, Dragonfly managing partner Haseeb Qureshi stated that crypto’s ambition to replace traditional property rights and legal contracts did not materialize as anticipated.
He stated that the large on-chain transactions can feel intimidating due to risks such as draining wallets, whereas traditional bank transfers typically do not evoke the same response.